CLOUDFLARE DOWN WORLDWIDE: Here is the cause.
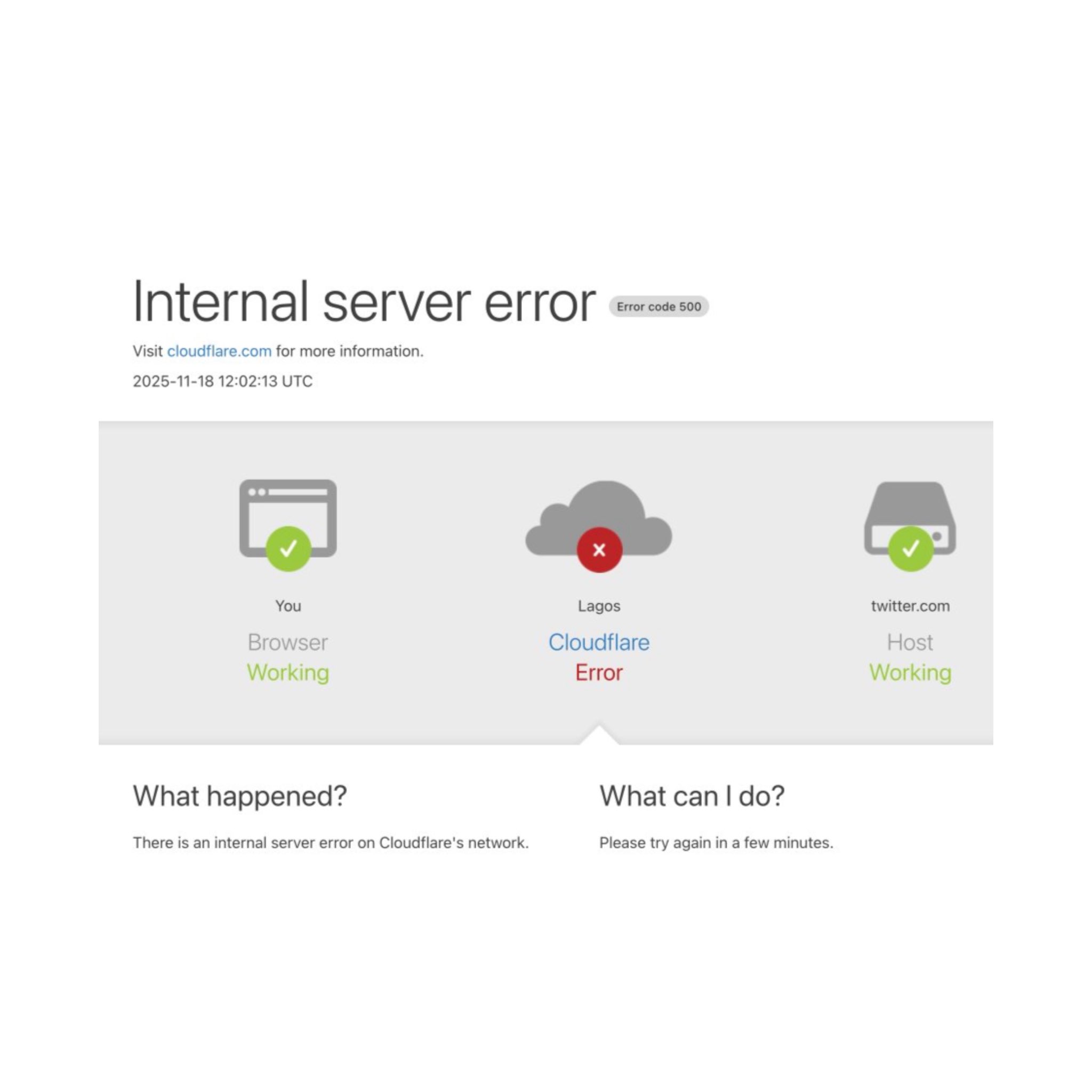
Cloudflare Confirms Major Global Outage: Latent Bug Triggered Massive Network Degradation — Not an Attack
Cloudflare has officially acknowledged a major global service outage that disrupted large portions of the Internet earlier today. According to Dane Knecht, Senior Vice President at Cloudflare, the incident originated from an internal issue rather than a cyberattack.
The outage affected countless businesses, platforms, and services that rely on Cloudflare’s network for performance, security, and availability — including global websites, APIs, and enterprise services.
What Happened? Cloudflare Reveals Root Cause
Cloudflare issued a transparent statement explaining that the disruption was caused by a latent bug inside a core service responsible for bot-mitigation and traffic inspection.
A routine configuration update triggered that hidden bug, causing the affected component to crash and cascading into a widespread network degradation across multiple Cloudflare services.
Cloudflare emphasized that this incident was not related to an attack, DDoS, or external threat actor activity.
The outage was entirely internal.
Why It Spread So Quickly
The affected internal service plays a critical role in routing and inspecting global traffic. When it began to fail:
- Load balancers were overwhelmed
- Dependent services began returning errors
- Latency and packet loss increased
- CDN and WAF features degraded worldwide
- Some regions experienced full service interruption
Because Cloudflare sits in front of a significant percentage of the global web, even a single malfunctioning subsystem can cause broad ripple effects.
Impact on Customers
Businesses relying on Cloudflare experienced:
- Website downtime
- API disruptions
- Broken login flows
- Failed DNS/HTTP requests
- Slowed or blocked access to critical platforms
For many, this resulted in revenue loss, operational delays, and user-experience problems across their digital services.
Cloudflare acknowledged the severity of the impact, calling the downtime unacceptable.
Cloudflare’s Response and Next Steps
Cloudflare assured customers that engineers stabilized the issue quickly, and a full post-incident analysis is underway. The company is now:
- Reviewing the faulty configuration change
- Deploying patches for the latent bug
- Improving safety checks for future updates
- Enhancing internal monitoring and rollback mechanisms
Their statement highlighted the importance of customer trust and promised increased safeguards to prevent this type of failure from happening again.
Why This Matters for the Security Community
Even though the incident wasn’t an attack, it serves as a reminder of a crucial cybersecurity principle:
Sometimes the most significant outages come from inside — not from hackers.
Misconfigurations, latent bugs, and fragile dependencies remain among the top causes of global-scale service failures.
For organizations depending on cloud vendors, redundancy strategies and multi-provider architectures remain essential.
Conclusion
Cloudflare’s transparency in acknowledging the issue is a positive step, but the event underscores how deeply integrated Cloudflare is in modern Internet infrastructure — and how even small internal glitches can escalate into global incidents.
A full technical report is expected from Cloudflare in the coming hours.
CTO POST:
I won’t mince words: earlier today we failed our customers and the broader Internet when a problem in
@Cloudflare
network impacted large amounts of traffic that rely on us. The sites, businesses, and organizations that rely on Cloudflare depend on us being available and I apologize for the impact that we caused.
Transparency about what happened matters, and we plan to share a breakdown with more details in a few hours. In short, a latent bug in a service underpinning our bot mitigation capability started to crash after a routine configuration change we made. That cascaded into a broad degradation to our network and other services. This was not an attack.
That issue, impact it caused, and time to resolution is unacceptable. Work is already underway to make sure it does not happen again, but I know it caused real pain today. The trust our customers place in us is what we value the most and we are going to do what it takes to earn that back.