Tools: Open Source Reading Across Books With Claude Code
LLMs are overused to summarise and underused to help us read deeper.
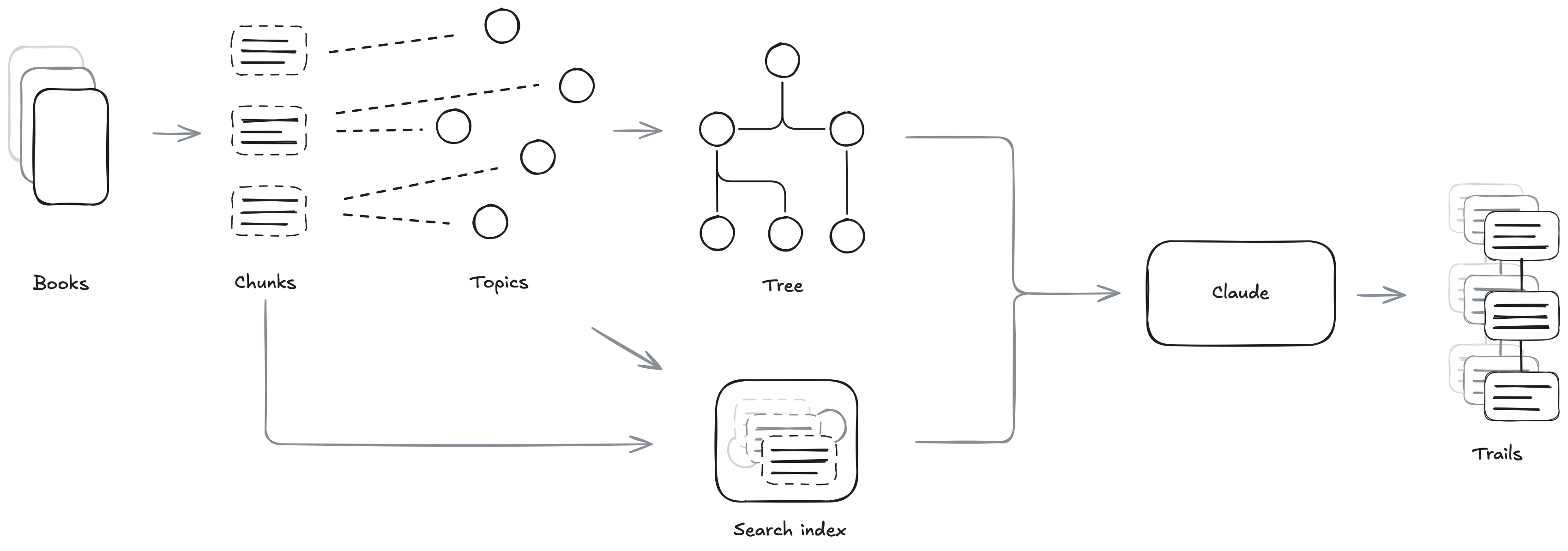
To explore how they can enrich rather than reduce, I set Claude Code up with tools to mine a library of 100 non-fiction books. It found sequences of excerpts connected by an interesting idea, or trails.
Here’s a part of one such trail, linking deception in the startup world to the social psychology of mass movements (I’m especially pleased by the jump from Jobs to Theranos):
The books were selected from Hacker News’ favourites, which I previously scraped and visualized.
Claude browses the books a chunk at a time. A chunk is a segment of roughly 500 words that aligns with paragraphs when possible. This length is a good balance between saving tokens and providing enough context for ideas to breathe.
Chunks are indexed by topic, and topics are themselves indexed for search. This makes it easy to look up all passages in the corpus that relate to, say, deception.
This works well when you know what to look for, but search alone can’t tell you which topics are present to begin with. There are over 100,000 extracted topics, far too many to be browsed directly. To support exploration, they are grouped into a hierarchical tree structure.
This yields around 1,000 top-level topics. They emerge from combining lower-level topics, and not all of them are equally useful:
However, this Borgesian taxonomy is good enough for Claude to piece together what the books are about.
Claude uses the topic tree and the search via a few CLI tools. They allow it to:
Source: HackerNews

