Powerful Compressed Filesystems À La Language Models
Every systems engineer at some point in their journey yearns to write a filesystem. This sounds daunting at first - and writing a battle-tested filesystem is hard - but the minimal surface area for a “working” FS is surprisingly small, simple, and in-distribution for coding agents.
In fact, one of my smoke tests for new coding models is seeing how good of a filesystem they can one-shot! At some point, I had quite a few filesystems lying around - and coding models were getting pretty good - which made me wonder if the models were intelligent enough to actually model the filesystem engine itself?
A filesystem is the perfect black-box API to model with wacky backends (see “Harder drives”), and besides the joy of training an LLM for fun - there were a few deeper truths about language models that I wanted to explore.
So I set upon training a filesystem. Building on top of one of my throwaway FUSEs, a few rounds with Claude repurposed it to loopback against the host with added logging, two things I needed to generate reference fine-tuning data:
I then wrote a filesystem interaction simulator, which sampled various operations against a sandboxed LoggingLoopbackFS to generate diverse FUSE prompt/completion pairs. Concretely, I captured only the minimal set of operations needed for R/W-ish capability (no open, xattrs, fsync etc).
Alongside the FUSE operation, I captured the full filesystem state at every turn. I experimented with various formats, including an ASCII-art representation, but ultimately settled on XML since it enforces prompt boundaries clearly and had canonical parsers available.
With prompts including the FUSE operation + XML filesystem tree, the model learned two forms of completions:
Once I had clean, representative, and diverse filesystem simulation data, actually running SFT was pretty straightforward on Modal. Over a few iteration cycles spread across nibbles of spare time, I ended up with ~98% accuracy on a hold-out eval after 8 epochs of SFT on a N=15000 dataset with Qwen3-4b.
Most of my time here was spent cleaning generated data and ensuring we represented every FUSE operation sufficiently + generated enough “complex” trees to learn on.
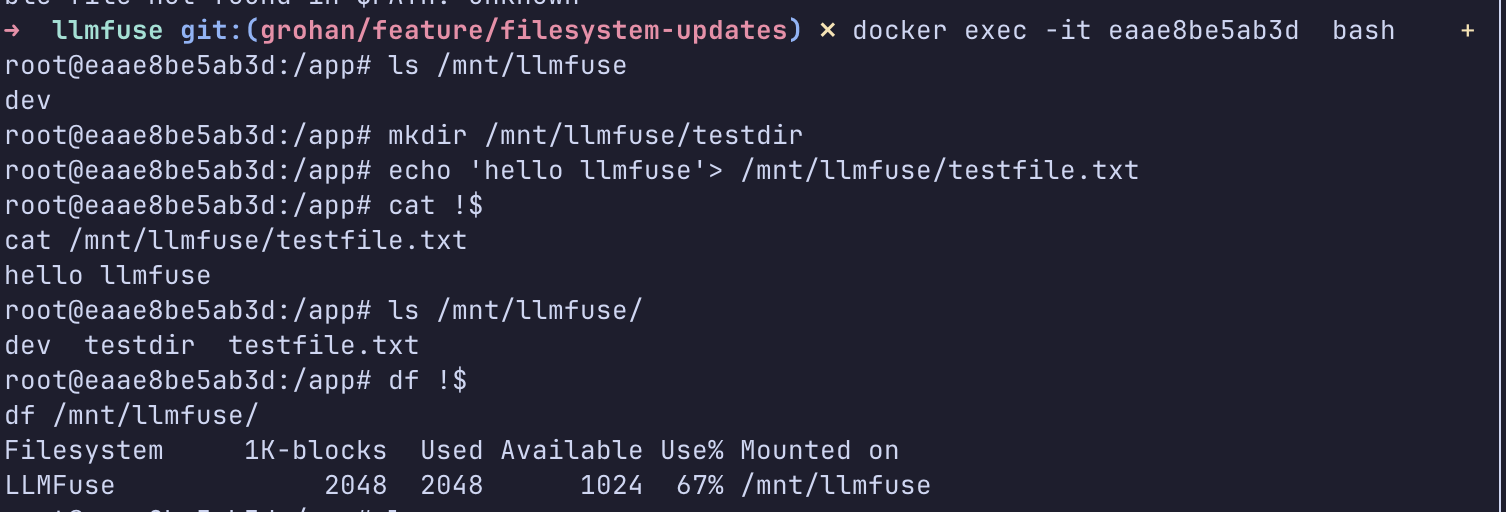
At this point, I wrote … possibly the smallest filesystem I’ve seen… to give my model a spin in the real world. Every FUSE operation was a passthrough to the LLM, for example:
Source: HackerNews
