Powerful Software Ate The World. Federation Will Eat Embeddings
Someone told you to pivot to AI. Add an AI layer. “We need to be AI-first.”
Fair enough. So you start thinking: what does AI need? Data. Obviously.
So the playbook writes itself: collect data in a central place, set up a vector database, do some chunking, build a RAG pipeline, maybe fine-tune a model. Then query it. Ship the chatbot. Declare victory.
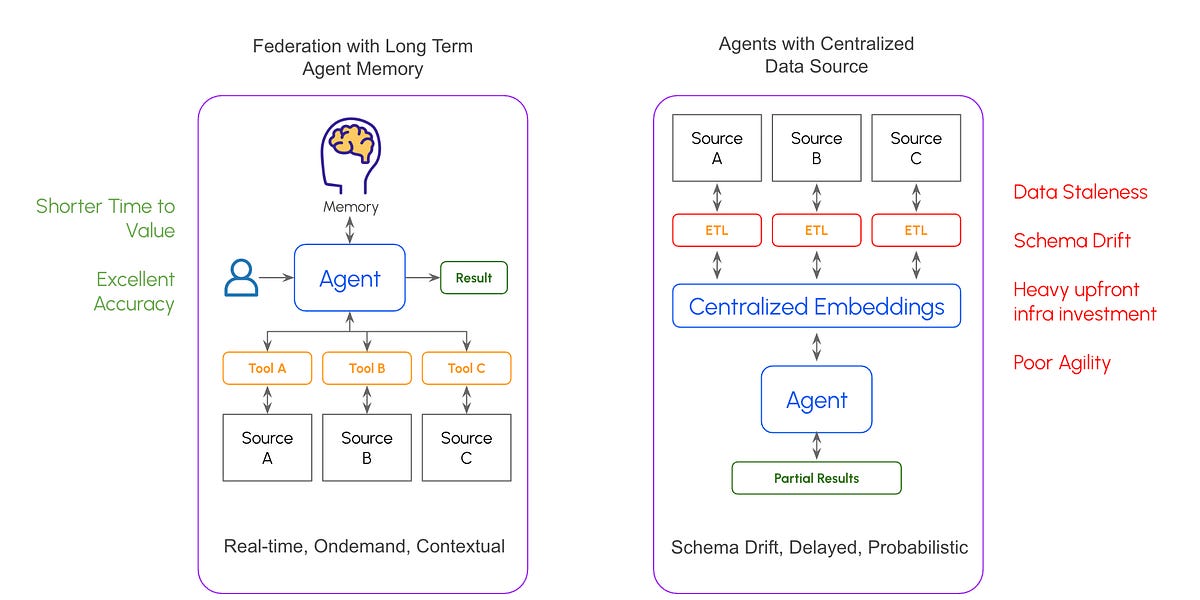
This is what I call the AI centralization tax. Not the cost of having a data warehouse, that’s often justified. The tax is building a parallel AI-specific data infrastructure on top of what you already have: vector databases, embedding pipelines, chunking strategies, custom models. A whole new layer, just for AI.
Here’s the thing: you might eventually need some of that. But probably not yet. And probably not for the use cases you think.
You likely already have systems that hold your data: CRMs, support platforms, billing systems, maybe a data warehouse. The question isn’t whether to centralize data (you probably already have). The question is whether AI needs its own separate copy, transformed into embeddings, stored in yet another database.
If you’re going after differentiation, if you’re trying to prove unit economics, if you’re racing to stay ahead of competitors, building AI-specific infrastructure before seeing any returns is a strategic mistake. You’re creating a parallel data estate for questions you haven’t validated.
And here’s the trap: once you’ve invested months building embedding pipelines and vector infrastructure, it’s painful to pivot even when better options emerge. That’s not just technical debt. That’s strategic lock-in to an architecture that may already be obsolete.
Someone asks: “What’s the health of this customer?”
You don’t need a RAG pipeline for that. You don’t need a vector database. You don’t need your own model. You don’t need a data warehouse with months of ETL work.
Source: HackerNews
