Tools: Show Hn: I Built A Sub-500ms Latency Voice Agent From Scratch
I’ve spent the last six months working on a startup, building agent prototypes for one of the largest consumer packaged goods companies in the world. As part of that work, our team relied on off-the-shelf voice agent platforms to help the company operate more effectively. Though I can’t go into the business details, the technical takeaway was clear: voice agents are powerful, and there are brilliant off-the-shelf abstractions like Vapi and ElevenLabs that make spinning up voice agents a breeze. But: these abstractions also hide a surprising amount of complexity.
Just a few days before I started writing this, ElevenLabs raised one of the largest funding rounds in the space, and new frontier models like GPT-5.3 and Claude 4.6 dropped. This made me wonder: could I actually build the orchestration layer of a voice agent myself? Not just a toy experiment, but something that could have close to the same performance as an all-in-one platform like Vapi?
To my surprise, I could. It took ~a day and roughly $100 in API credits - and the result outperformed Vapi's equivalent setup by 2× on latency, achieving ~400ms end-to-end response times.
This essay walks through the full build: why voice agents are deceptively hard, how the turn-taking loop works, how I wired together STT, LLM, and TTS into a streaming pipeline, and how geography and model selection made the biggest difference. Along the way, you can listen to audio demos and play with interactive diagrams of the architecture.
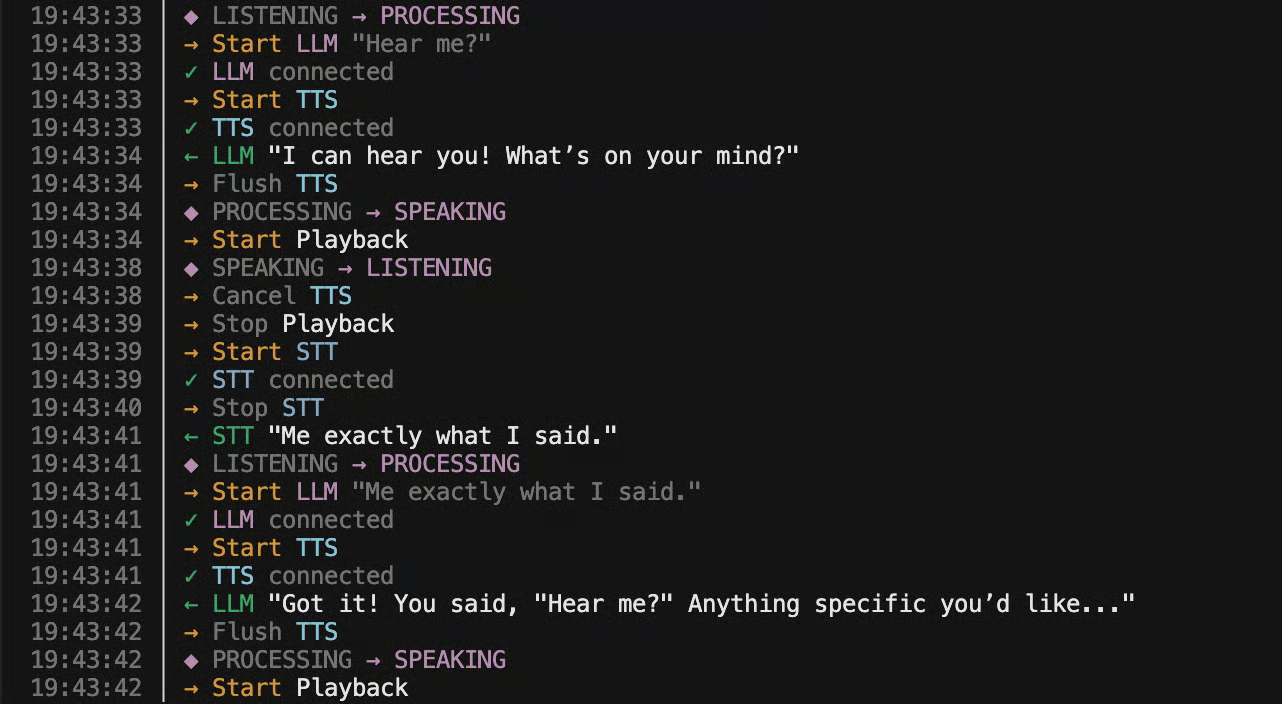
Voice agents are a big step-change in complexity compared to agentic chat.
Text agents are relatively simple, because the end-user’s actions coordinate everything. The model produces text, the user reads it, types a reply, and hits “send.” That action defines the turn boundary. Nothing needs to happen until the user explicitly advances the flow.
Voice doesn’t work that way. The orchestration is continuous, real-time, and must carefully manage multiple models at once. At any moment, the system must decide: is the user speaking, or are they listening? And the transitions between those two states are where all the difficulty lives.
When the user starts speaking, the agent must immediately stop talking - cancel generation, cancel speech synthesis, flush any buffered audio. When the user stops speaking, the system must confidently decide that they’re done, and start responding with minimal delay. Get either wrong and the conversation feels broken.
This isn’t as simple as measuring loudnes
Source: HackerNews
